타입캐스트, 60여 AI 성우 중 일부 음성에 고음질 적용 및 모든 음성 품질 개선
서비스 만족도 전반 상승 기대… 더욱 고도화된 음성 생성 기술 선도
[비즈월드] 미디어·엔터테인먼트·방송·교육 등 다양한 분야의 콘텐츠 제작을 위한 클라우드 플랫폼 서비스를 제공하는 AI 음성 전문 기업인 ‘네오사피엔스(대표 김태수)’가 자사 인공지능 성우 서비스 ‘타입캐스트(TypeCast)’의 고음질 다운로드 베타 서비스를 실시한다고 최근 밝혔다.
타입캐스트는 현재 서비스 중인 60여 종의 AI 성우 중 일부 음성에 고음질 다운로드 베타 서비스를 실시, 그 외 모든 AI 성우의 음질도 전면 개선했다고 한다. 일부 음성에 적용된 고음질 다운로드 베타 서비스는 유료 회원 한정으로 제공한다.
이용 방법은 타입캐스트 편집창에서 ‘HD’ 표시된 AI 성우를 선택 후 음성을 다운로드하면 기존보다 확연하게 좋아진 고음질 콘텐츠를 생성할 수 있다. 고음질 다운로드 기능은 점차적인 개발 과정을 거쳐 향후 모든 AI 성우 음성에 적용될 예정이다.
김태수 네오사피엔스 대표는 “이번 고음질 다운로드 베타 서비스는 타입캐스트 론칭 후 꾸준히 증가하고 있는 가입자들 및 장기 이용 고객들에게 보다 뛰어난 음질로 보답하고자 시작했다”라고 설명했다.
김 대표는 이어 “일부 음성 뿐 아니라 현재 서비스 중인 모든 AI 성우의 음질을 전반적으로 개선해 모든 이용자들의 만족도가 더욱 높아질 것으로 예상되며, 이번 고음질 베타 서비스를 시작으로 더욱 고도화된 음성 생성 기술을 선도하겠다”라고 말했다.
타입캐스트는 프로 연기자의 목소리를 활용한 데이터를 기반으로 현재 60여 종의 다양한 음성을 제공 중인 인공지능 성우 서비스다.
지난 2019년 4월 베타 서비스 론칭을 시작으로 가파른 성장세를 보이고 있으며, 올해 7월 들어 가입자 수 5만명을 돌파했다.
타입캐스트의 인공지능 성우 음성은 네오사피엔스가 보유한 원천 기술로 문장의 맥락 파악, 감정 및 운율 표현이 우수해 오디오북 등 고수준의 목소리 연기를 요하는 콘텐츠 제작에 최적화된 것이 특징이다.

네오사피엔스는 퀄컴(Qualcomm)과 카이스트(KAIST) 출신의 음성 분야 인공지능 전문가 팀이 2017년 11월에 설립한 스타트업이다. 올해 초 컴퍼니케이파트너스, 우리기술투자 등으로부터 시리즈A 투자를 유치해 누적 투자액 62억원을 기록했다. CES 2020에서 AI 음성 합성 기술을 활용한 성우 서비스를 소개해 주목을 받았으며 지난 6월 서울시 ‘CAC 글로벌 서밋 2020’에서 IT·언택트 분야 혁신기업으로도 선정되기도 했다.
네오사피엔스만의 인공지능 음성 서비스는 딥 러닝(Deep learning) 기술을 바탕으로, 전문 성우 등 특정인의 음성을 학습해 다양한 운율, 감정을 우수하게 표현한다. 이와 관련된 다수 특허 출원, 주요 방송사 등과 협업하며 인공지능을 통한 미디어, 엔터테인먼트 분야의 혁신을 주도 중이다.
실제로 비즈월드가 이 회사의 특허 현황을 확인한 결과 2018년 3월 29일 ‘비디오 번역 및 립싱크 방법 및 시스템’이라는 명칭의 특허를 출원한 이후 2019년에는 총 5개의 특허를 잇달아 선보였다.
2019년 1월 11일 ▲‘다중 언어 텍스트-음성 합성 방법’과 ▲‘다중 언어 텍스트-음성 합성 모델을 이용한 음성 번역 방법 및 시스템’ ▲‘기계학습을 이용한 텍스트-음성 합성 방법, 장치 및 컴퓨터 판독가능한 저장매체’ 등 3건의 음성 관련 특허를 동시에 선보였다.
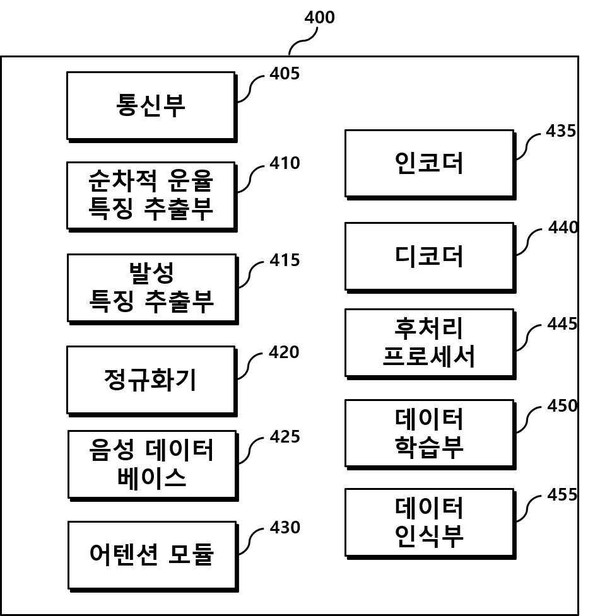
이어 2019년 8월 1일에는 ‘순차적 운율 특징을 기초로 기계학습을 이용한 텍스트-음성 합성 방법, 장치 및 컴퓨터 판독가능한 저장매체’, 그해 11월 14일에는 ‘대상 화자 음성과 동일한 음성을 가진 컨텐츠를 검색하는 방법 및 이를 실행하기 위한 장치’를 출원했다.
해당 6건의 출원특허 중 처음 내놓았던 ‘비디오 번역 및 립싱크 방법 및 시스템’을 제외하고 나머지 5건은 현재 등록을 위한 심사 중이다.
관련기사
- [특허 in 마켓] 롯데푸드 ‘파스퇴르’, 자체 특허 기술 적용한 '쾌변' 리뉴얼 및 '쾌변 콜라겐' 출시
- [특허 in 마켓] 자이글, ‘산소를 포함하는 기능성 화장료 조성물’ 특허 취득
- [특허 in 마켓] 국내외서 특허 취득한 유산균으로 만든 탑헬스 여성유산균 ‘우먼스밸런스’, 유럽 CE인증까지 획득
- [특허 in 마켓] 천연스토리, 느타리버섯 추출 엽산 추출 기술 특허 출원
- [특허 in 마켓] 에이빌코리아, ‘욕세럼’ 공식 상표권 이전등록 받아
- [특허 in 마켓] 결혼예물브랜드 ‘민준주얼리’, 디자인 특허 취득한 ‘오브’ 웨딩밴드 실물 공개
- [단독, 특허 in 마켓] “2개 회사의 특허가 합쳐 출시됐다”…한미헬스케어 ‘완전두유’, 공식 브랜드사이트 론칭
- [특허 in 마켓] 글로벌 FPS IP 가진 ‘㈜엔에스스튜디오’, IP 사업본격화